목차
- 정수 상수와 진법
- 실수 상수와 부동소수점
- 문자와 문자열 상수
- 아스키코드
- 비트와 바이트
1. 정수 상수와 진법
서론
C 프로그래밍에는 몇 가지 데이터를 사용합니다.
그것들은 정수,실수, 문자, 문자열, 등이 있는데. 일단 상수에 대해 먼저 알아봅시다.
상수(constant)는 불변하는 숫자로, 변수(variable)와 다르게 고정되어 있습니다.
정수 상수는 일반적으로 아라비아 숫자 0~9까지, 그리고 양수와 음수로 구별되며,
정수 상수는 일반적으로 네 가지 진법(2진수, 8진수, 10진수, 16진수)으로 사용할 수 있습니다.
진법별 수 체계
진법은 수를 표현하는 방법이고, n진법은 n-1만큼의 수를 자리수에 최대로 담는 것입니다. 그러니까..
0부터 16까지를 각 진법으로 표현하자면..
| 2진수 | 8진수 | 10진수 | 16진수 |
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 10 | 2 | 2 | 2 |
| 11 | 3 | 3 | 3 |
| 100 | 4 | 4 | 4 |
| 101 | 5 | 5 | 5 |
| 110 | 6 | 6 | 6 |
| 111 | 7 | 7 | 7 |
| 1000 | 10 | 8 | 8 |
| 1001 | 11 | 9 | 9 |
| 1010 | 12 | 10 | A |
| 1011 | 13 | 11 | B |
| 1100 | 14 | 12 | C |
| 1101 | 15 | 13 | D |
| 1110 | 16 | 14 | E |
| 1111 | 17 | 15 | F |
| 10000 | 20 | 16 | 10 |
입니다, 이해가 되나요?
안 되신다고요? 사실 이건 수학의 영역입니다.
이해가 어렵다면 시간의 개념을 생각해 보세요.
1일은 24시간이고, 1시간은 60분이고, 1분은 60초입니다.
어떻게 보면 시간도 일종의 진법이에요, 숫자의 묶음 단위를 달리 하는 거죠.
진법의 표현
일반적으로, 수학에서는 이러한 진법을 사용하기 위해 밑수 10002 등을 사용해서 표시하지만, 프로그래밍에서는 이런게 안됩니다. 아니 HTML을 쓰면 <sup>2</sup> 로 표현이 되기는 하는데..
아무튼, 이러한 것을 해결하기 위하여 8진수는 숫자 앞에 0을, 16진수는 숫자 앞에 0x를 적어서 구분합니다.
2진수는요? 라고 하면 0B 또는 0b를 사용합니다.
저게 뭘 의미하냐고요? 0(0o)은 8진수(Octal)을, 0x는 16진수(Hexadecimal)을, 0B(0b)는 2진수 (Binary)를 의미합니다.
아참, 0은 사실 0o로도 사용됩니다. 특히 파이썬에서 말이죠.
여담으로, 0x가 0H가 아닌 이유는 직관성의 문제와 경로의존성 때문인데, 가장 간단하게 설명하자면 C가 나온 시기에는 타자기가 구식이라 H보다 x가 더 눈에 잘 보이기 때문이에요.
즉, 0B1100과 014와 12와 0xC는 모두 같다는 겁니다.
한번 실습해 볼까요?
#include <stdio.h>
int main()
{
printf("%d\n", 0b1100); //2진수 정수 상수 출력
printf("%d\n", 014); //8진수 정수 상수 출력
printf("%d\n", 12); //10진수 정수 상수 출력
printf("%d\n", 0xC); //16진수 정수 상수 출력
return 0;
}이렇게 하면..
12
12
12
12
가 나온답니다.
진법의 출력
물론 다른 진수들을 10진수로만 출력할 수 있는건 아니에요.
이전편의 변환문자에서, %d는 10진수 자료형이지만..
%o와 %x 등을 통해서 8진수와 16진수로 출력할 수도 있어요.
이번에도 한번 해봅시다.
#include <stdio.h>
int main()
{
printf("%o\n", 47); //8진수 정수 상수 변환
printf("%d\n", 47); //10진수 정수 상수 변환
printf("%x\n", 47); //16진수 정수 상수 변환
return 0;
}이번에는 47을 넣었지만, 원한다면 어떤 수든 넣을 수 있어요.
출력은 다음과 같습니다.
57
47
2f
2. 실수 상수와 부동소수점
실수(Real numbers)는 일반적으로 R이라 부르지만, 프로그래밍에서는 f라 부릅니다. 이유가 뭘까요?
일반적으로 실수는 정수와는 다르게 세 부분으로 쪼개집니다.
정수는 부호부와 정수부 2개로 쪼개지는 반면, 실수(부동소수점형)는 부호부와 지수부, 그리고 가수로 쪼개집니다.
고정소수점방식은 부호부와 정수부, 소수부로 쪼개지는데 이건 잘 안 써요.

그럼 왜 그랬을까요?
이유는 간단한데, 더 넓은 범위를 표현하기 위해서입니다.
고정소수점 방식은 말그대로 고정소수점이에요. 만약 소수부에 쓸 수 있는 저장공간이 65535개라면, 소수의 최대 자리수는 5자리가 한계입니다.
하지만 부동소수점 방법은 달라요, 만약 가수부에 쓸 수 있는 저장공간이 65535개라면, 1을 65535개로 쪼갠 다음 들어오는 소수 입력을 잘 맞춰놓은 다음, 지수부를 이용해 단위수를 증폭시켜요.
덕분에 부동소수점은 고정소수점과 다르게 매우 길어지는 소수를 저장할 수 있어요.
그게 얼마정도 차이냐고요?
고정소수점은 104 ~ 105정도지만, 부동소수점은 1038(float) ~ 10308(double) 까지 표현할 수 있어요, 수십억 배 이상의 차이죠.
하지만 이전에 말했다시피 1을 저 숫자만큼 쪼개서 표현하기 때문에 정확하게 표시되는 유효숫자에 한계가 있어요,
float형은 유효숫자를 6자리까지, double형은 유효숫자를 16자리까지 보장해주기때문에 가능하다면 double형을 쓰는 것이 좋습니다.
유효숫자가 뭐냐고요? 오차 없는 범위까지의 자릿수죠...
거기다 실수연산을 할 때에는 조심해야 하는데, 유효숫자가 같더라도 뒤에 숨어있는 숫자들이 달라질 수 있기 때문에, 실수연산에는 동치(==)보다는 (<=이나, >=)연산을 쓰는게 좋아요.

지수부가 이해가 안 되신다면, 한번 프로그래밍을 해보시죠.
#include <stdio.h>
int main()
{
printf("%f\n", 3.14e-4); //지수 형태의 실수를 소수점 형태로 출력
printf("%.2e\n", 0.000314); //소수점 형태의 실수를 지수 형태로 출력
return 0;
}짜잔.
이러면 출력은 어떻게 될까요?
0.000314
3.14e-04
가 나와요. e+n일 경우에는 숫자에 10^n을 곱하고, e-n일 경우에는 숫자에 1/10^n을 곱해요.
사실 이건 수학의 영역이라.. 일단 이정도에서 마무리하죠.
3. 문자와 문자열 상수
C에는 글자도 표현해야겠죠.
표현을 위해서 문자와 문자열 상수를 사용하는데, 문자와 문자열의 차이는 크게 두 종류가 있어요.
일단, 문자는 작은따옴표('')를 사용하고, 문자열은 큰따옴표("")를 사용해요.
그리고, C의 문자열은 사실 "문자의 배열" 과 동등한데.. 이건 나중에 배열에서 다시 한번 배우고.
한번 코드를 짜보죠.
#include <stdio.h>
int main()
{
printf("%c\n", 'A'); //문자 상수 출력
printf("%s\n", "Apple"); //문자열 상수 출력
return 0;
}짜잔
출력은 어떨까요?
A
Apple
뭐, 당연하죠..
자, 이렇게 문자열 상수에 대해서 알아봤는데..
이전에도 말했지만, 컴퓨터는 알고있는게 2진수밖에 없어요.
숫자야 진법변환으로 읽는다 해도, 문자는 어떻게 아는걸까요?
4. 아스키코드
그 해답이 바로 아스키코드 ASCII (American Standard Code for Information Interchange, 미국 정보 교환 표준 부호)입니다.
사실, 컴퓨터는 문자를 저장하지 않아요. 문자 대신 숫자로 바꿔서 저장합니다.
아스키코드는 사람이 사용하는 기호를 컴퓨터 안에서 표현하는 방법에 대해 약속한 것인데, 예를 들어 A라는 문자가 있으면 컴퓨터는 이를 01000001 등으로 바꿔서 저장하고, 출력할 때 이 2진수를 보고 아! A구나! 하면서 출력해줍니다.
아스키코드에는 컴퓨터에 필요한 128개의 문자가 들어가있는데,
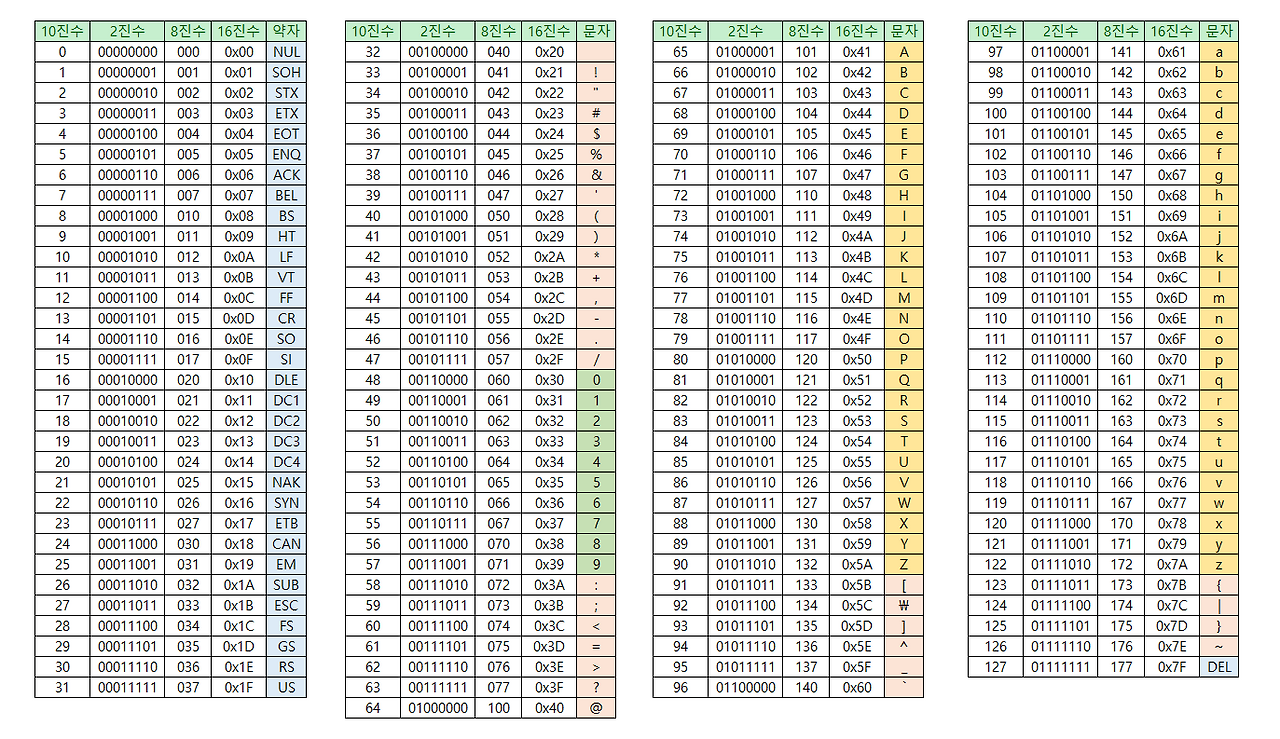
당연하게도 외우면 좋지만 안외웁니다. 이딴걸 왜 알아요.
하지만 아스키코드의 48이 1이고, 65가 A고, 97이 a인 것은 알아두면 좋아요, 필요하면 저 숫자만큼 늘려서 원하는 숫자 찾으면 되니까.. 사실 컴파일러 자체에서 찾을수 있기도 하고말이죠.
가령, 프로그래밍에서 이런 것도 가능한데..
#include <stdio.h>
int main()
{
printf("%d\n", 'A'); //문자 A에 해당하는 아스키코드 출력
printf("%c\n", 36); //아스키코드 36에 해당하는 문자 출력
return 0;
}출력은? 어떻게 될까요?
65
$
이렇게 된답니다.
한국어는 어디있냐고요? 그건 유니코드 쪽인데..
5. 비트와 바이트
앞서서, 컴퓨터는 모든 데이터를 0101001001..같은 2진수로 변환한다고 말합니다.
이때, 0은 일종의 비트(bit)입니다. 이러한 비트가 8개가 모이면 1바이트(byte)가 되죠.
| 1 |
| 0 |
그러니까, 이게 비트입니다.
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 |
이게 바이트고요.
정수 상수를 컴파일하면 4바이트(int)로 저장되고, 실수 상수는 4바이트(float) 혹은 8바이트(double)로 저장됩니다.
저 바이트 덩어리가 여러개.. 아스키코드는 1바이트입니다.
아무튼, 이 바이트의 맨 앞을 이용해 양수와 음수를 구별하고, 비트 수에 따라서 표현할 수 있는 값의 범위도 달라집니다.
재미있게도 이러한 바이트 덕분에 오버플로 문제 또한 생기는데,
8비트의 경우 스타크래프트의 킬수와 업그레이드 한계인 255
16비트의 경우 마인크래프트의 마법부여 한계인 32767
32비트의 경우 유명한 2,147,483,647 등이 있습니다.
이러한 비트를 통해서 컴퓨터는 1의 보수 연산, 2의 보수 연산 등을 처리하는데, 아.. 이건 좀 어려운거라서 스킵하죠.
여담으로, 바이트가 1024개 모이면 킬로바이트, 킬로바이트가 1024개 모이면 메가바이트, 기가바이트, 테라바이트..
요즘은 페타바이트도 나오는거같던데말이에요.
(사실 32기가 USB가 실제로 32기가가 안 되는 이유가, 컴퓨터 표현으로는 1024바이트 = 1킬로바이트로 읽는데 실제로는 1000바이트 = 1킬로바이트이기 때문에 크기가 약간 줄어드는 현상이...)
